CQRS - Simple architecture
This post was also published on Future Processing - Technical Blog
Some say: “CQRS is hard!”
Is it? Well, I used to think the same! But when I started writing my first piece of software using CQRS, it quickly turned out that it is rather uncomplicated. What is more, I think that in long term it is much easier to maintain software written in this way.
I have started to think, what is the reason that people see it as hard and complex at the beginning? I have a theory: it has rules! Entering the world with rules is always uncomfortable, we need to adjust to rules. In this post I’d like to prove that in this case those rules are quite digestible.
On the way to CQRS…
Basically, we can say that CQRS is an implementation of Command Query Separation principle to the architecture of software. What I noticed during my work in this approach is that there is a couple of steps between simplest CQS implementation and real full-blown CQRS. I think that those steps smoothly introduce rules I have mentioned before.
While the first steps are not fulfilling my definition of CQRS (but are sometimes so called), they can still introduce some real value to your software. Each step introduces some interesting ideas that may help to structure or clean your codebase/architecture. Usually, our journey starts with something that looks like this:

This is typical N-Layer architecture as all of us probably know. If we want to add some CQS here, we can „simply” separate business logic into Commands and Queries:

If you are working with legacy codebase this is probably the hardest step as separating side-effects from reads in spaghetti code is not easy. In the same time this step is probably the most beneficial one; it gives you an overview where your side effects are performed.
Hold for a second! You are talking about CQS, CQRS, but you have not defined what Command or Query is!
That is true. Let’s define them now! I’ll give you my personal, intuitive definition of Command and Query here. It is not exhaustive and definitely should be deepened before implementation.
Command – First of all,firing command is the only way to change the state of our system. Commands are responsible for introducing all changes to the system. If there was no command, the state of the system remains unchanged! Command should not return any value. I implement it as a pair of classes: Command and CommandHandler. Command is just a plain object that is used by CommandHandler as input value (parameters) for some operation it represents. In my vision command is simply invoking particular operations in Domain Model (not necessarily one operation per command).
Query – Analogically, query is a READ operation. It reads the state of the system, filters, aggregates and transforms data to deliver it in the most useful format. It can be executed multiple times and will not affect the state of the system. I used to implement them as one class with some Execute(...) method, but now I think that separation to Query and QueryHandler/QueryExecutor may be useful.
Going back to the diagram, I need to clarify one more thing; I’ve smuggled here one additional change, Model became the Domain Model. By the Model I understand a group of containers for data while Domain Model encapsulates essential complexity of business rules. This change is not directly affecting our further considerations as we are interested in architectural stuff here. But it is worth mentioning that despite the fact that the command is responsible for changing state of our system, the essential complexity should be placed in the Domain Model.
OK, now we can add new command or write new query. After short period of time it will be quite obvious that Domain Model that works well for writing is not necessarily perfect for reading. It is not a huge discovery that it would be easier to read data from some specialized model:
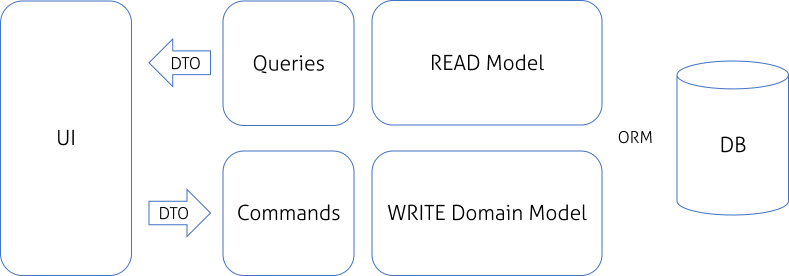
We can introduce separated model, mapped by ORM and use it to build our queries, but in some scenarios, especially when ORM introduces overhead, it would be useful to simplify this architecture:
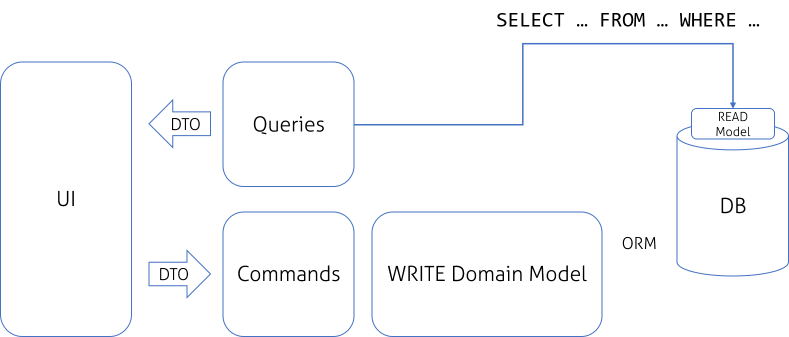
I think that this particular change should be well thought out! Now the problem is that we still have READ and WRITE model separated only at the logical level as both of them shares common database. That means we have separated READ model but most likely it is virtualized by some DB Views, in better case Materialized Views. This solution is OK if our system is not suffering from performance issues and we remember to update our queries along with WRITE model changes. The next step is to introduce fully separated data models:
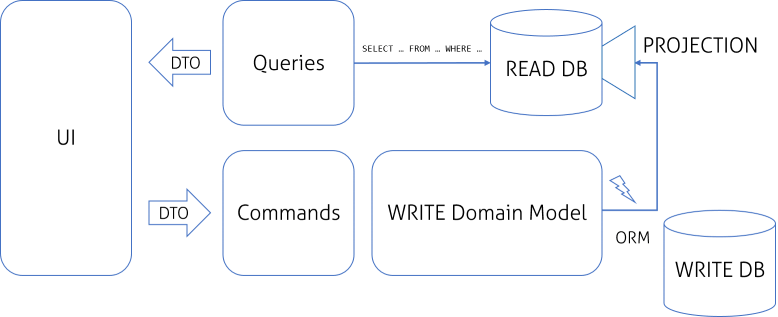
From my point of view this is the first model that fulfills original idea presented by Greg Young, now we can call it CQRS. But there is also a catch! I’ll write about it later.
CQRS != Event Sourcing
Event Sourcing is an idea that was presented along with CQRS, and is often identified as a part of CQRS. The idea of ES is simple: our domain is producing events that represent every change made in system. If we take every event from the beginning of the system and replay them on initial state, we will get to the current state of the system. It works similarly to transactions on our bank accounts; we can start with empty account, replay every single transaction and (hopefully) get the current balance. So, if we have stored all events, we can always get the current state of the system.
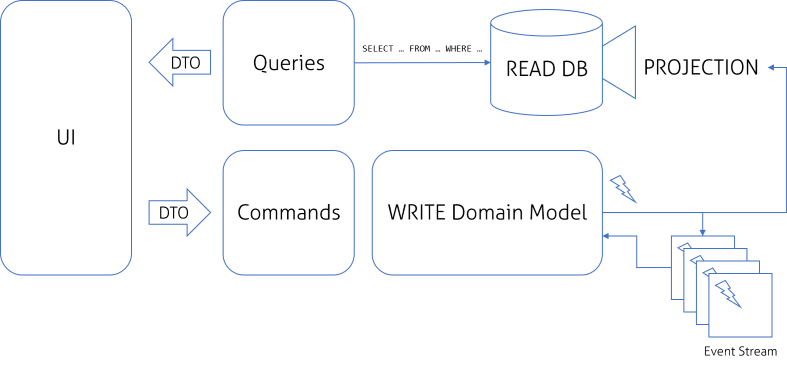
While ES is a great method to store the state of the system is not necessarily required in CQRS. For CQRS, it is not important how Domain Model is actually stored and this is just one of options.
READ and WRITE model
The idea of separated models seems to be quite clear and straight-forward when we are reading about CQRS but it seems to be unclear during implementation. What is the responsibility of WRITE model? Should I put all data into my READ model? Well, it depends!
WRITE model
I like to think about my WRITE model as about the heart of the system. This is my domain model, it makes business decisions, it is important. The fact that it makes business decisions is crucial here, because it defines major responsibility of this model: it represents the true state of the system, the state that can be used to make valuable decisions. This model is the only source of truth.
If you want to know more about designing domain models I recommend reading about Domain Driven Design technique philosophy.
READ model
In my first attempt to CQRS I have used WRITE model to build queries and … it was OK (or at least worked). After some time we reach the point in the project where some of our queries were taking a lot of time. Why? Because we are programmers and optimization is our second nature. We designed our model to be normalized, so our READ side were suffering from JOINs. We were forced to pre calculate some data for reports to keep it fast. That was an quite interesting, because in fact we have introduced a cache. And from my point of view this is the best definition of READ model: it is a legitimate cache. Cache that is there by design, and is not introduced because we have to release project and non-functional requirements are not met.
The label READ model can suggest that it is stored in a single database and that’s it. In fact READ model can be very complex, you can use graph database to store social connections and RDBMS to store financial data. This is the place where polyglot persistence is natural.
Designing good READ side is a series of trade offs, e.g. pure normalization vs pure denormalization. If your project is small and most of your reads can be efficiently made against WRITE model, it will be a waste of time and computing power to create copy. But if your WRITE model is stored as a series of events, it would be useful to have every required data available without replaying all events from scratch. This process is called Eager Read Derivation and from my point of view it is one of the most complex things in CQRS, this is a catch I have mentioned earlier. As I said before, READ side is a form of cache and as we know:
There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
I said that it is a „legitimate” cache, this word has also additional meaning for me that in our system we have obvious reasons to update the cache. Events produced by our Domain Model are natural reasons to update READ model.
Eventual Consistency
If our models are physically separated, it is natural that synchronisation will take some time, but this time somehow is very scary for the business people. In my projects, if every part was working correctly, time when READ model was out-of-sync was usually negligible. However, we will definitely need to take time hazards into account during development in more complex systems. Well designed UI is also very helpful in handling eventual consistency.
We have to assume that even if READ model is updated synchronously with WRITE model, user will still make decisions based on stale data. Unfortunately, we can not be sure that when data is presented to user (eg. rendered in web browser) it is still fresh.
How I can introduce CQRS to my project?
I believe that CQRS is so simple that there is no need to introduce any framework. You can start with the simplest implementation with less than 100 lines and then extend it with new features when it will be needed. You do not need any magic, because CQRS is simple and it simplifies the software. Here is my implementation:
I defined couple of interfaces that describes commands and theirs execution environment. Why have I used two interfaces to define single command? I did this because I want to keep parameters as plain object that can be created without any dependencies. My command handler will be able to request dependencies from DI container and there will be no need to instantiate it by hand anywhere except in tests. In fact, ICommand interface works here rather as marker that tells developer if he can use this class as a command.
This definition is very similar with one difference that IQuery interface also defines the result type of the query. This is not the most elegant solution but as a result returned types are verified at the compile time.
My CommandDispatcher is relatively short and it has only one responsibility to instantiate proper command handler for a given command and execute it. To avoid handcrafting commands registrations and instantiations I have used DI container to do this for me, but if you do not want to use any DI container you can still do that on your own. I said that this implementation will be simple and I believe it will. The only problem may be noise introduced by generic types and it may be discouraging at the beginning. This implementation is definitely simple in usage. Here is a sample command and handler:
To execute this command you only need to pass SignOnCommand to the dispatcher:
And that’s it. QueryDispatcher looks very similar, the only difference is that it returns some data and thanks to generic stuff I wrote earlier Execute method returns strongly typed result:
As I said, this implementation is very extensible. For example, we can introduce transactions to our command dispatcher without changing its original implementation by creating decorator:
By using this pseudo-aspects we can easily extend both Command and Query dispatchers. You can add Fire-and-Forget manner of command execution as well as extensive logging.
As you can see CQRS is not that hard, the basic idea is clear but you need to follow some rules. I am sure that this post is not covering the entire thing, that is why I want to recommend you some more reading.